言語モデル(げんごモデル、英: language model)は、単語列に対する確率分布を表わすものである。
解説
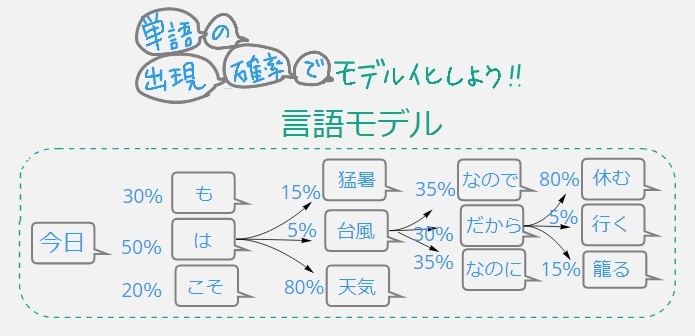
言語モデルは、長さがm個の単語列が与えられたとき、その単語列全体に対しての確率 を与える。この確率分布は、1つまたは複数の言語のテキストコーパスを使用して、言語モデルを訓練することによって得られる。しかし、言語は無限に有効な文を表現することができるため、言語モデリングは、訓練データでは遭遇しないような言語的に有効な単語列にゼロでない確率を割り当てることが課題となる。この問題を克服するために、マルコフ仮定や、回帰型ニューラルネットワークあるいはトランスフォーマー(transformer)などのニューラルアーキテクチャなど、さまざまなモデリング方法が考案されている。
言語モデルは、計算言語学におけるさまざまな問題に役立っている。当初は、低確率で無意味な単語列を予測を防ぐために音声認識での使用から始まった。現在では、機械翻訳(翻訳候補の順位付け)や、より人間に近いテキストを生成する自然言語生成、品詞タグ付け、構文解析、光学文字認識、手書き文字認識、文法誘導、情報検索など、幅広い用途に利用されている。
情報検索においては、クエリ尤度モデルにおいて言語モデルが用いられる。この方法では、コレクション内のすべての文書に、個別の言語モデルが関連付けられている。そして各文書は、その文書の言語モデル に対するクエリ の確率 に基づいて順位付けされる。この目的のため一般に、ユニグラム(unigram)言語モデルが利用される。
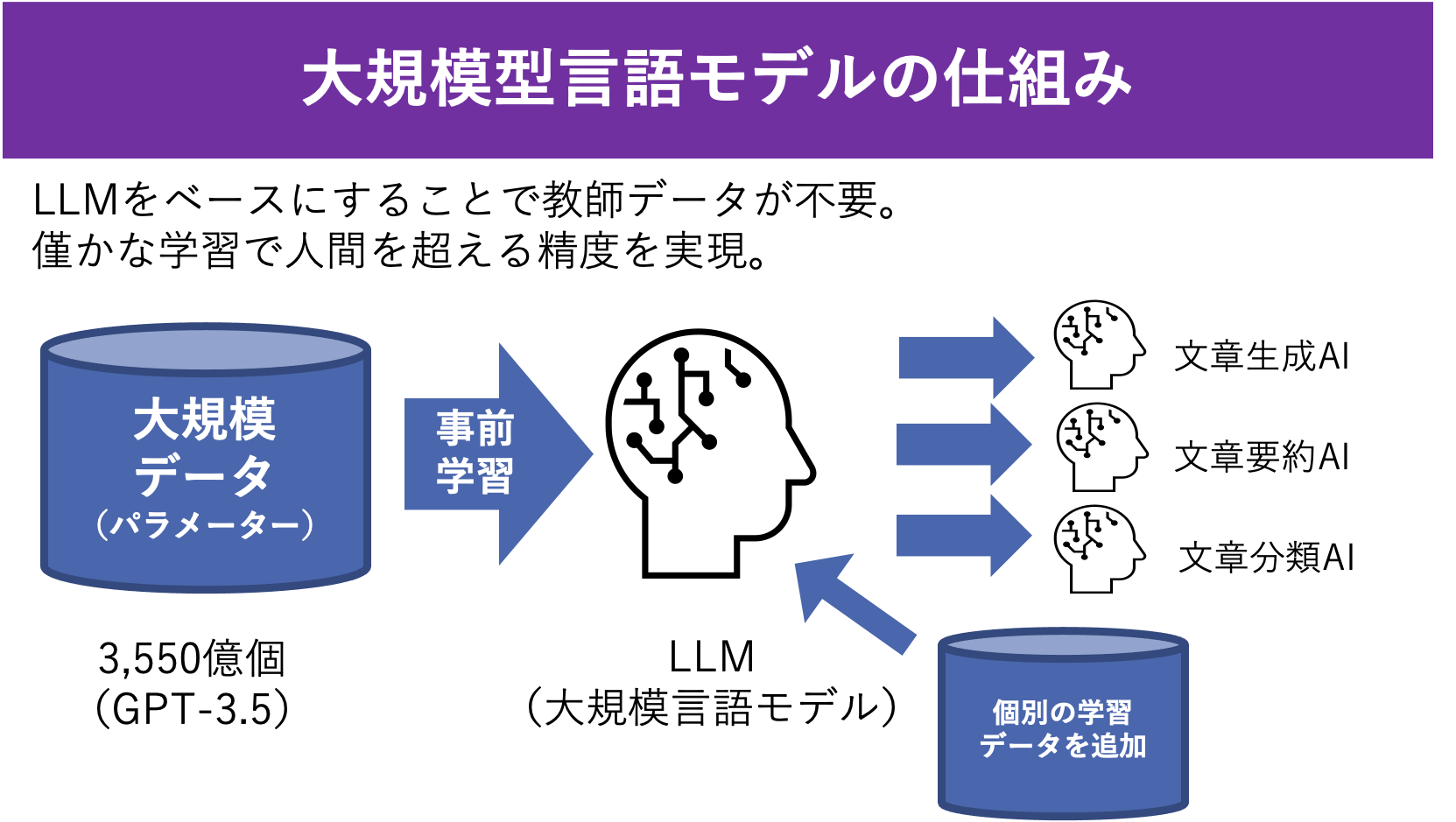
2018年以降、大規模言語モデル(LLM)が登場し、大きな発展がみられた。これらのモデルは、数十億個の学習可能なパラメータを持つディープ・ニューラルネットワークで構成され、ラベルなしテキストの膨大なデータセットで訓練される。LLMは、さまざまな自然言語処理タスクで目覚ましい成果を示し、研究の焦点が汎用的なLLMの使用へと移り変わっていた。
2024年初頭、専門家はすでに、言語モデル開発の焦点は大規模な言語モデルから小規模なモデルへと移行し、2025年におけるMITのブレークスルー技術の第3位は小規模な言語モデルであり、言語モデルは大規模から小規模へと進展している。
モデルの種類
n-gramモデル
n-gram言語モデルは、マルコフ過程に基づいて単語列をモデル化するものである。このモデルでは、単語列内の次の単語の確率が、先行する単語の固定サイズのウィンドウにのみ依存すると仮定することで単純化する。たとえば、bigramモデルは先行する1つの単語のみを考慮し、trigramモデルは先行する2つの単語を考慮し、n-gramモデルは先行するn-1単語を文脈として考慮する。
たとえば、bigram言語モデルは、「I saw the red house(赤い家が見えた)」という文の確率を次のようにモデル化する。ここで、 と は文の開始と終了を示す特別なトークンである。
これらの条件付き確率は、テキストコーパスの一部分の頻度カウントに基づいて推定することができる。たとえば、 は、コーパス内での単語「I」に続いて「saw」が出現する割合として単純に推定できる。スパース性の問題(たとえば、コーパス内で「red house」というbigramの出現数がゼロの場合)は、特に大きなコンテキストウィンドウを使用する場合に、平滑化手法によって基本的なマルコフモデルを修正する必要がある。
指数関数モデル
最大エントロピー言語モデルでは、単語とn-gramの履歴との関係を符号化する特徴関数を使用する。言語モデルは次の式で表される。ここで、 は分配関数、 はパラメータベクトル、 は特徴関数である。最も単純な形では、特徴関数は特定のn-gramの存在を示す指標にすぎない。モデルの最適なのために、 の事前分布を利用するか、何らかの形で正則化を行うことが有効である。指数関数型の言語モデルの一つの例として、対数双線形モデルがある。
ニューラルネットワーク
ニューラル言語モデルは、連続空間言語モデル(continuous space language models)とも呼ばれ、単語の連続的な表現または埋め込みを使用して予測を行う。これらのモデルでは、ニューラルネットワークが使用されている。
連続空間の埋め込みは、言語モデリングにおける「次元の呪い」を軽減するために有効な手法である。訓練に用いるテキストの大きさ応じて語彙に含まれる固有の単語数も増える。このため、単語列の可能な組みわせ数が指数関数的に増加することにより、データ疎性の問題が発生する。そのため、確率を適切に推定するためには統計が必要となる。この問題を回避するため、ニューラルネットワークでは単語の表現を分散させる手法をとり、ネットワーク内の重みの非線形な組み合わせとして表現する。また、ニューラルネットは言語関数を近似していると捉えることもできる。この目的に使用できるニューラルネットのアーキテクチャには、順伝播型と回帰型の2種類がある。前者は単純であるが、後者の方がより一般的である[要解説]。
ニューラルネット言語モデルは一般に、語彙 のすべての単語 について確率分布を予測することを目的とした確率的分類器として構築・訓練される。 すなわち、ネットワークは、与えられた言語的コンテキストに基づいて、語彙の確率分布を予測するように訓練される。これは、バックプロパゲーションを用いた確率的勾配降下法などの標準的なニューラルネットワークの学習アルゴリズムによって行われる。コンテキストは、先行する単語の固定サイズのウィンドウとすることができ、ネットワークは先行する k 個の単語を表す特徴ベクトルからを予測する。もう一つの選択肢として、「過去」と「未来」の単語を特徴として使用し、推定確率をとする、バッグ・オブ・ワードモデル(bag-of-words model)と呼ばれるモデルもある。文脈中の単語の特徴ベクトルを連続演算で連結すると、このモデルは連続バッグ・オブ・ワード(Continuous bag-of-words、CBOW)アーキテクチャと呼ばれる。
第3の選択肢は、skip-gramと呼ばれる言語モデルである。これは先の問題を逆にして、与えられた単語から、文脈を出力するようにニューラルネットワークを訓練させるもので、CBOWよりも訓練に時間がかかるが、わずかに良い性能を得ることができる。その目標は、訓練用の単語列 が与えられたとき、平均対数確率を最大化することである。ここで訓練文脈の大きさ k は、中央の単語 の関数とすることができる。skip-gramモデルとbag-of-wordsモデルは、word2vecプログラムの基礎をなしている。 ニューラルネット言語モデルを使用する際に良く行われるのが、実際の確率を計算するのではなく、ネットワークの「隠れ層」に符号化された分散表現を単語の表現として利用するものである。各単語は「単語埋め込み」と呼ばれる n 次元の実数ベクトルが割り当てられる。ここで n は、出力層より前の層の大きさである。特徴的なのは、skip-gramモデルの表現が、単語間の意味的関係を線型結合としてモデル化し、それにより構成性の形式を捉えることである。たとえば、このようなモデルでは、単語 w をその n 次元ベクトル表現に対応付ける関数 v があるとき、という式が成立し、ここで ≈ は正確には右辺が左辺の値の最近傍として定義される。
その他
位置言語モデル(positional language model)は、テキスト内で特定の単語が、すぐに隣接していなくても、近くに出現する確率を評価するものである。同様に、bag-of-conceptsモデルは、「今日、私はとても素敵なクリスマスプレゼントをたくさん買った」のような情報量の多い文章でも、buy_christmas_present のような複数単語表現に関連付けて、そのセマンティクス(意味)を利用するものである。
手話のモデリングにおいては、ニューラルネットワークで一定の成功をあげているが、他の技術が必要であることを研究者は認識している。
Generative Spoken Language Model (GSLM) は音声を入力とした言語モデルである。文字列を入力として一切利用しない。音声は言語情報以外にパラ言語情報・非言語情報を含んでいるため、音声を入力とするGSLMが獲得する表現にはこれらの情報もコードされていると期待される。
評価とベンチマーク
言語モデルの品質は、通常、典型的な言語指向タスクを反映した、人間が作成したサンプルベンチマークとの比較によって評価される。あまり確立されていないが、言語モデルに固有の特性を調べたり、2つのモデルを比較する品質テストの方法もある。言語モデルは通常は動的であり、訓練で遭遇したデータから学習することを目的としているため、提案されたモデルの中には、学習曲線を調べることによって、学習速度を評価するものもある。
言語処理システムを評価するために、いくつかのデータセットが開発されており、次のようなものがある。
- 言語学的許容性コーパス(Corpus of Linguistic Acceptability、CoLA)
- GLUEベンチマーク(GLUE benchmark)
- マイクロソフトリサーチ・パラフレーズコーパス(Microsoft Research Paraphrase Corpus、MRPC)
- 多ジャンル自然言語推論(Multi-Genre Natural Language Inference、MultiNLI)
- 質問自然言語推論(Question Natural Language Inference、QNLI)
- Quora質問ペア(Quora Question Pairs、QQP)
- テキスト含意認識(Recognizing Textual Entailment、RTE)
- テキスト意味的類似度ベンチマーク(Semantic Textual Similarity Benchmark、STS)
- スタンフォード質問応答データセット(Stanford Question Answering Dataset、SQuAD)
- スタンフォードセンチメントツリーバンク(Stanford Sentiment Treebank、SST)
- Winograd NLI(WNLI)
- BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC, OpenBookQA, NaturalQuestions, TriviaQA, RACE, MMLU (Measuring Massive Multitask Language Understanding), BIG-bench hard, GSM8k, RealToxicityPrompts, WinoGender, CrowS-Pairs. (LLaMa Benchmark)
批評
GPT(Generative pre-trained transformer)のような現代の言語モデルは、特定のタスクにおいて人間に匹敵する能力を発揮するが、認知モデルとしての妥当性は不確かになっている。たとえば、回帰型ニューラルネットワークの場合、人間が学習しないパターンを学習したり、人間が学習するパターンを学習できずに失敗することが知られている。
参考項目
備考
脚注
推薦文献